
Recruiting Part 2 [In-Depth Tutorial]
June 14, 2021
Introduction
Welcome to Part 2 of the Recruiting Use Case Tutorial! In Part 1, we covered some key background on the Person Search API and worked through a simple warmup exercise in order to illustrate the features of the API. In the process, we introduced a framework for building queries, as well as some techniques for sending and receiving data from the API endpoint. In Part 2, we’ll take what we learned and demonstrate how to build a search query using our job description from the recruiting use case scenario. We’ll also take a look at some techniques for debugging and improving queries. Finally, we’ll show you how to use the advanced features of the Person Search API to build expert-level queries.
Prerequisites
This tutorial will build directly off of Part 1 of the Recruiting Tutorial, which we strongly recommend reading prior to working through this tutorial. In particular, we’ll be focusing on the query building framework introduced in the previous post. We will pick up directly where Part 1 left off, but first, let’s quickly refresh ourselves on the recruiting scenario we’ll be working through.
The Recruiting Scenario
Today, we'll imagine that we are an up-and-coming tech company in the Virtual/Augmented Reality (VR/AR) space: Virtually Reality, Inc. We recently raised a large round of funding and one of our first goals is to build out our engineering department. Suppose we have the following job role that we would like to hire for:
Software Engineer, Full Stack Web (Remote - US)
Department: Engineering
Location: San Francisco, CA (Remote)
Virtually Reality's Engineering Team is seeking a Web Front-End Engineer to build intuitive, scalable, and easy-to-use web applications to support the development of our Virtually Real (TM) platform used to deploy our massive open-world VR social experiences.
Responsibilities
Design and implement full-stack web features in Java and Javascript.
Qualifications
You have a BS, MS, or PhD in Computer Science or a related technical field, or equivalent experience.
You have 3+ years of experience working as a software engineer on building web applications with Javascript and web frameworks in a professional setting, particularly using React.
You have experience with server-side technologies, such as Java.
Bonus Points if:
You have built web applications involving manipulation of geospatial, customer management, or analytics data.
You have worked on websites that are cross-device and browser compatible.
You have experience in the VR / AR space
In this scenario, we have several openings for this position, so we want to find multiple highly-qualified candidates to fill this role. We’re aiming to run an automated email campaign to ~2,000 candidates.
First Query
In Part 1, we finished by working through a basic warmup exercise to go end-to-end with a simple query. Now, let's take a look at building a more realistic query for our recruiting scenario. Our goal to start with is to use our Query Building Framework to design a search query (this time based on our job description), then to send the request and pull the top 10 matches like in our warmup.
Building the Query
Let’s now work through the Query building framework to turn our job description into a search query for the Person Search API.
Step 1: Definition
Specify which person profiles you want to find as precisely as possible.
We can define our target profiles by pulling requirements directly from our job posting:
Location: must be currently living in the US
Education: must have "BS, MS, or PhD in Computer Science or a related technical field, or equivalent experience"
Experience: must have "3+ years of experience working as a software engineer"
Required Skills: "Javascript, react, web frameworks, Java"
Ideal Experience 1: "web applications involving manipulation of geospatial, customer management, or analytics data"
Ideal Experience 2: "worked on websites that are cross-device and browser compatible"
Ideal Skills/Interests: "experience in the VR / AR space"
Because we are interested in reaching out to our target profiles, we'll also add the following additional requirement:
Contact Info: profile must have some contact info
Simplifying the Definition
While this step was very straightforward for our simple warmup example from before, we'll see that it can be more of an iterative process for complex queries. As a general rule of thumb, start small and simplify your search definition in order to make it more precise.
Demonstration: Simplifying our Definition To illustrate this iterative process, let's briefly focus on just the education portion of our definition to see what roadblocks we would find moving through the rest of the framework: Peeking ahead, step 2 would be to pick relevant fields from the Person Schema, which in this case might be:
education.degrees: "A list of canonical degrees associated with this education object"
education.majors: "A list of majors associated with this education object"
But then how would we represent equivalent technical experience? We could avoid this question by returning back to our definition and simplify it by removing that part. Continuing on to step 3, we would find that both these fields are canonicalized, but in step 4, we would now need to specify the criteria for these fields. We would need to answer the question: what are relevant fields for Computer Science? While this seems doable, we could again return back to Step 1 and simplify the definition to only focus on Computer Science degrees (discarding the "related technical field" part). In this way, we could iteratively simplify and refine our definition.
Simplified Definition
With some practice (and particularly familiarity with the Person Schema), it will become easier to directly construct a definition that is easy to translate into query criteria from the start. Alternatively, you can arrive at a similar result by iteratively refining the definition as you work through the Query Building Framework.
Whichever method you use, here's what a simplified target profile definition might look like:
Location: must be currently living in the US
Education: must have majored in CS at some point
Experience: must have worked in a software engineering role
Required Skills: must have skills in all of [Javascript, react, web frameworks, Java]
Ideal Experience 1: should have skills in any of [geospatial, customer management or analytics data
Ideal Experience 2: discarded to simplify
Ideal Skills/Interests: should have skills or interests in any of virtual reality (vr) or augmented reality (ar)
Contact info: must have a linkedin profile
Step 2: Fields (Person Schema)
Look at the person schema documentation to see what profile fields are available to build queries with.
The following fields from the person schema appear relevant for the simplified definition in Step 1:
Location:
location_country: "the current country of the person"
Education:
education.majors: "A list of majors associated with this education object"
Experience:
experience.title.role: "A person's job title derived role"
experience.title.sub_role: "A person's job title derived subrole. Each subrole maps to a role"
Required Skills:
skills: "Skills associated with the profile"
Ideal Experience 1:
skills: "Skills associated with the profile"
Ideal Skills/Interests:
skills: "Skills associated with the profile"
interests: "Interests associated with the profile"
Contact Info:
linkedin_url: "Main linkedin profile for this record based on source agreement"
Step 3: Formatting (Person Manual)
Check the person manual documentation to see how to format the values for each field
Checking the formatting and canonicalization for the fields in Step 2 we find:
Location:
location_country: This field is canonicalized (List of Canonical Countries)
Education:
education.majors: This field is canonicalized (List of Canonical Majors)
Experience:
experience.title.role: This field is canonicalized (List of Canonical Roles)
experience.title.sub_role: This field is canonicalized (List of Canonical Subroles)
Required Skills:
skills: This is a free-text field (so it is formatted in lowercase without leading/trailing whitespaces)
Ideal Experience 1:
skills: This is a free-text field (so it is formatted in lowercase without leading/trailing whitespaces)
Ideal Skills/Interests:
skills: This is a free-text field (so it is formatted in lowercase without leading/trailing whitespaces)
interests: This is a free-text field (so it is formatted in lowercase without leading/trailing whitespaces)
Contact Info:
linkedin_url: Formatted as "linkedin.com/in/username"
Step 4: Criteria (Field Mapping)
Define query criteria for the fields you've selected
Next, we'll define the query criteria for each of the fields in Step 3:
Location:
location_country: must exactly equal united states (because united states is a canonical value and the field mapping for location_country is keyword which supports term-based matching)
Education:
education.majors: must exactly equal computer science (because computer science is a canonical value and the field mapping for education.majors is keyword which supports term-based matching)
Experience:
experience.title.role: must exactly equal engineering (because engineering is a canonical value and the field mapping for experience.title.role is keyword which supports term-based matching)
experience.title.sub_role: must exactly equal software (because software is a canonical value and the field mapping for experience.title.sub_role is keyword which supports term-based matching)
Required Skills:
skills: must exactly equal javascript
skills: must exactly equal react
skills: must exactly equal java
skills: must exactly equal web frameworks
The field mapping for skills is keyword which supports term-based matching, which is why we can specify exact terms (like javascript and web frameworks).
Ideal Experience 1:
skills: must exactly equal geospatial
skills: must exactly equal customer management
skills: must exactly equal analytics
Ideal Skills/Interests:
skills: must exactly equal virtual reality
skills: must exactly equal vr
skills: must exactly equal augmented reality
skills: must exactly equal ar
interests: must exactly equal virtual reality
interests: must exactly equal vr
interests: must exactly equal augmented reality
interests: must exactly equal ar
Like skills, the field mapping for interests is keyword which supports term-based matching.
Contact Info:
linkedin_url: must exist
Step 5: Logic
Construct the logic to join the criteria together into a full query.
For Step 5, we'll join all of our query criteria to align with our initial target profile definition:
Required criteria:
location_country must exactly equal united states
AND
education.majors: must exactly equal computer science
AND
experience.title.role: must exactly equal engineering
AND
experience.title.sub_role: must exactly equal software
AND
skills: must exactly equal javascript
AND
skills: must exactly equal react
AND
skills: must exactly equal java
AND
skills: must exactly equal web frameworks
AND
linkedin_url: must exist
Ranking criteria (more is better):
skills: must exactly equal geospatial
OR
skills: must exactly equal customer management
OR
skills: must exactly equal analytics
OR
skills: must exactly equal virtual reality
OR
skills: must exactly equal vr
OR
skills: must exactly equal augmented reality
OR
skills: must exactly equal ar
OR
interests: must exactly equal virtual reality
OR
interests: must exactly equal vr
OR
interests: must exactly equal augmented reality
OR
interests: must exactly equal ar
Step 6: Syntax
Write the query using one of the supported Person Search API syntaxes
Finally, we can construct our query using Elasticsearch syntax using the logic from the previous step as follows:
query_es = {
"query": {
"bool": {
"must": [
# Location
{"term": {"location_country": "united states"}},
# Education
{"term": {"education.majors": "computer science"}},
# Experience
{"term": {"experience.title.role": "engineering"}},
{"term": {"experience.title.sub_role": "software"}},
# Required Skills
{"term": {"skills": "javascript"}},
{"term": {"skills": "react"}},
{"term": {"skills": "java"}},
{"term": {"skills": "web frameworks"}},
# Contact Info:
{"exists": {"field": "linkedin_url"}}
],
"should": [
# Ideal Experience 1
{"term": {"skills": "geospatial"}},
{"term": {"skills": "customer management"}},
{"term": {"skills": "analytics"}},
# Ideal Skills/Interests
{"term": {"skills": "vr"}},
{"term": {"skills": "virtual reality"}},
{"term": {"skills": "ar"}},
{"term": {"skills": "augmented reality"}},
{"term": {"interests": "vr"}},
{"term": {"interests": "virtual reality"}},
{"term": {"interests": "ar"}},
{"term": {"interests": "augmented reality"}},
]
}
}}
The logic from Step 5 translates relatively cleanly into the full Elasticsearch syntax. The key aspects to notice are that:
All the required criteria are located in the must section, which joins the query criteria together by a logical AND operation
The remaining ideal criteria are located in the should section, which joins these criteria together by a logical OR operation
This should section also serves the purpose of ranking the match results for this query, where matches satisfying more of the should criteria will appear higher in the list of results (given that they satisfy the criteria in the must clause)
Sending the Query and Retrieving the Results
With our query built, we will follow the exact same process we did for our warmup query, by sending the search request, counting the total number of matches and retrieving the top 10 matches:
# Send search request
query = query_es # we will focus on elasticsearch syntax moving forward
size = 10 # number of results to pull down (up to 100)
success, results = send_person_search_request(query, use_sql, size)
# Count total number of results:print(f"Total number of matches in PDL database: {results['total']}")
# Look at results:# Number of results pulled down:print(f"Number of records retrieved: {len(results['data'])}")
# Job title and locations of matches:for idx, profile in enumerate(results['data']):
print(f"{idx+1}) "
f"Job Title: {profile['job_title']} - "
f"Location: {profile['location_country']}")
# Save profiles to csv (and download):# Note: You may need to enable browser permissions to download files
filename = 'candidate_profiles_first_query.csv'
save_profiles_to_csv(results['data'], filename)
files.download(filename)
Total number of matches in PDL database: 5
Number of records retrieved: 51) Job Title: None - Location: united states
2) Job Title: software engineer - Location: united states
3) Job Title: engineering leader - Location: united states
4) Job Title: software engineer - Location: united states
5) Job Title: None - Location: united states
Wrote 5 lines to: 'candidate_profiles_first_query.csv'
Unfortunately, the results for our first real query are quite disappointing/ With this query, we see that there are only 5 matches found in the entire PDL dataset (which contains close to 3 billion profiles)! Furthermore, the job titles of the profile matches do not seem like particularly strong matches for our job description.
However, we know that we simplified our query a fair amount (i.e. in Step 1), which means that potentially adding complexity back into our query might help us improve it (though we should be judicious in how we do this). In the next section, we'll take a look to see if we can figure out what went wrong and how we can improve our query from here.
Improved Query
Query Debugging
One handy way to try and debug search queries (particularly ones with many criteria) is to take a look at each query criteria individually. Specifically, testing each query individually to see the number of total matches found, and then testing adding in each query one-by-one to see how that affects the total number of matches as well. These two tests (individual and joint) are generally good sanity checks and can be quite informative.
To illustrate how these two tests work, let's use the following dummy query with 4 criteria:
query_es = {
"query": {
"bool": {
"must": [
criteria_1,
criteria_2,
criteria_3
],
"should": [
criteria_4,
criteria_5
]
}
}}
Because we are mostly interested in how the criteria affect the total number of matches found, we can ignore any criteria in the should clause (e.g. criteria_4 and criteria_5) since these criteria only impact the quality of a profile match, not whether the profile is a match or not.
As a result, the first test (checking each query individually), is done by removing all the criteria (1-4). Then testing each of the criteria in the must clause individually (i.e. just criteria_1, just criteria_2, and just criteria_3) by sending it in an API request and checking the value of the total field in the response.
Note: Set size=1 or remove the parameter (which defaults size to 1) when sending these test API requests to avoid unnecessarily using up search credits
The second test is similar except instead of only using one criteria at a time, the criteria are added one-by-one (so first just criteria_1, then criteria_1 + criteria_2, then criteria_1 + criteria_2 + criteria_3, etc).
Let's see the results from running both these tests on our poorly performing query from before:
analyze_criteria(query_es)
Individual Clause Demographics
1) Total Count: 974250700 - Criteria: {'term': {'location_country': 'united states'}}2) Total Count: 7153211 - Criteria: {'term': {'education.majors': 'computer science'}}3) Total Count: 49241147 - Criteria: {'term': {'experience.title.role': 'engineering'}}4) Total Count: 8955391 - Criteria: {'term': {'experience.title.sub_role': 'software'}}5) Total Count: 4699592 - Criteria: {'term': {'skills': 'javascript'}}6) Total Count: 83054 - Criteria: {'term': {'skills': 'react'}}7) Total Count: 5800076 - Criteria: {'term': {'skills': 'java'}}8) Total Count: 2063 - Criteria: {'term': {'skills': 'web frameworks'}}9) Total Count: 660815254 - Criteria: {'exists': {'field': 'linkedin_url'}}
Joint Clause Demographics
0) Total Count: 2471031735 - Criteria: {}1) Total Count: 974250700 - Criteria: {'term': {'location_country': 'united states'}}2) Total Count: 2294571 - Criteria: {'term': {'education.majors': 'computer science'}}3) Total Count: 1401675 - Criteria: {'term': {'experience.title.role': 'engineering'}}4) Total Count: 765709 - Criteria: {'term': {'experience.title.sub_role': 'software'}}5) Total Count: 299027 - Criteria: {'term': {'skills': 'javascript'}}6) Total Count: 5191 - Criteria: {'term': {'skills': 'react'}}7) Total Count: 3882 - Criteria: {'term': {'skills': 'java'}}8) Total Count: 5 - Criteria: {'term': {'skills': 'web frameworks'}}9) Total Count: 5 - Criteria: {'exists': {'field': 'linkedin_url'}}
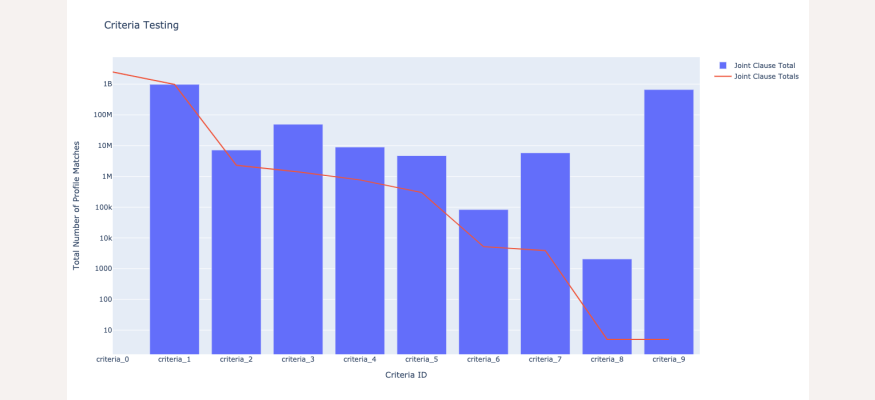
This figure shows the results from testing the criteria individually (blue bars) and jointly (red line). We can see that the number of results (red line) drops sharply after introducing criteria_8.
Let's take a look at the result of these tests. The results of the first test (testing the total number of matches for each individual criteria) is shown in the figure by the height of the blue bars, while the results of the second test (observing the total number of matches by adding in each query one-by-one) is shown by the red line graph. Note that the y-axis is logarithmic and criteria_0 indicates a search query with no criteria (e.g. the size of the total PDL person profile dataset).
From these plots, we can clearly see that criteria_8 ("skills must exactly equal web frameworks") is the biggest culprit for why our query returns so few matches due to the sharp drop in the red line (meaning adding this criteria significantly reduced the number of results for our overall query). Furthermore, we can see that this is caused by the relatively smaller height of the blue bar for this criteria. In other words, the total number of matches when running this query criteria individually is only 2063, meaning that only 2083 profiles in the entire PDL dataset have web frameworks listed as a skill.
After this, the next biggest bottleneck is criteria_6 ("skills must exactly equal react"), which has just over 83,000 profile matches for similar reasons. From these tests, we can conclude that building queries using specific skills can limit our results quite significantly.
Improvements
Based on our debugging, we've found that relying heavily on skills can be restrictive, so we need to find another way to build query criteria around these skills.
Given how small our total number of matches was (just 5), our primary goal for improving our query should be to increase the total number of matches. We can do this by:
Removing the bottlenecks from our use of skills criteria
Broadening some of our other criteria with low total match numbers (such as our education criteria)
Improving our Skills Criteria
The biggest limiting factor for our query is the skills criteria, so we'll start with these first. Perhaps the most obvious way to broaden our criteria is to remove the specific bottleneck skills (like web frameworks and react). This would certainly leave a larger pool of matches, but considering that our job description puts a strong emphasis on these two skills that likely means we will end up trading quality for quantity.
A second, slightly less obvious way to broaden this criteria is to consider both interests as well as skills. For example, instead of requiring "skills must exactly equal web frameworks", we might instead be happy with "either skills or interests must exactly equal web frameworks". This allows us to broaden our criteria as opposed to discarding it completely.
But, how would we translate this into query syntax? What we want is something like the following:
query_es = {
"query": {
"bool": {
"must": [
criteria_1,
(criteria_2 OR criteria_3)
],
"should": [
...
]
}
}}
In this pseudocode, our query would read as: criteria_1 must be true AND (either criteria_2 must be true OR criteria_3 must be true).
The solution to this is in fact nested queries! Since we want an OR operation between these criteria, we will have to use a nested should clause as follows:
query_es = {
"query": {
"bool": {
"must": [
criteria_1,
"bool": {
"should": [ criteria_2, criteria_3 ]
}
],
"should": [
...
]
}
}}
This gives us exactly what we need to broaden our queries, but as it turns out, there are a few more ways we could extend this:
We could do this for all our skills queries (not just web frameworks and react)
We could consider additional fields, such as skills, interests, and experience.title.name (i.e. any previous job title the person held)
We can change from a term-based match to a full-text match
In pseudocode, here's what the new skills criteria would look like:
query_es = {
"query": {
"bool": {
"must": [
criteria_1,
"bool": {
"should": [ criteria_2, criteria_3 ] # javascript
},
"bool": {
"should": [ criteria_4, criteria_5 ] # react
},
"bool": {
"should": [ criteria_6, criteria_7 ] # java
},
"bool": {
"should": [ criteria_8, criteria_9 ] # web frameworks
},
],
"should": [
...
]
}
}}
In code, this becomes the following:
# Must have at least one of the target keywords somewhere in profile:
target_skills = ['javascript', 'react', 'java', 'web frameworks']
target_skills_criteria = [
{"bool": {
"should": [
{"match": {"experience.title.name": kw}},
{"match": {"interests": kw}},
{"match": {"skills": kw}}
]
}}
for kw in target_skills
]
By doing this, we have simultaneously broadened all of our skills criteria in a meaningful way, which will increase the total number of matches for our query while still retaining key query criteria.
Improving our Education Criteria
The other way we observed that we could increase the total number of match results for our query was by broadening our education criteria. We saw this in our query debugging tests where the education criteria had the lowest total match size in the individual test after the skills criteria.
Luckily, broadening this criteria is much more straightforward than the query nesting we used for the skills queries. Specifically, instead of restricting our educational criteria to just match computer science degrees, we can add in all the related degrees listed in the List of Canonical Majors (remember our original job description considered degrees in "Computer Science or a related technical field"). The first step is to manually aggregate all the relevant degrees. With this list of all related majors, we can simply change our education criteria from a term query to a terms query as follows:
# previously: {"term" : {"education.majors": "computer science"}}
education_criteria = {"terms": {"education.majors": related_majors}}
Improving our Match Rankings
One last thing we might consider doing is improving the ranking order by broadening our ideal skills/interests the same way we did for our required skills (using query nesting).
This would look as follows:
# Define list of ideal skills/interests/keywords
ideal_skills = [
"geospatial",
"customer management",
"analytics",
"data"
"cross-device",
"browser compatible"
"VR",
"AR",
"virtual reality",
"augmented reality"]
# Build nested query for each skill# i.e. for each skill, skill must appear in one of:# [experience.title.name, interests, or skills]
ideal_skills_criteria = [
{"bool": {
"should": [
{"match": {"experience.title.name": kw}},
{"match": {"interests": kw}},
{"match": {"skills": kw}}
]
}}
for kw in ideal_skills
]
Putting our Improvements Together
Finally, let's put all of our improvements together into a single query:
query = {
"query": {
"bool": {
"must": [
# Location
{"term": {"location_country": "united states"}},
# Education
education_criteria,
# Experience
{"term": {"experience.title.role": "engineering"}},
{"term": {"experience.title.sub_role": "software"}},
# Required Skills
{"bool": {
"should":
target_skills_criteria
}
},
# Contact Info
{"exists": {"field": "linkedin_url"}}
],
# Ideal Skills/Interests
"should": ideal_skills_criteria
}
}}
Note that in the query above, the required skills criteria are combined in a nested should clause, which requires that for every profile at least one required skill must appear in either the experience.title.name, skills, or interests fields.
Sending and Receiving Query Results
As we've done before, let's now send our improved query in an API request and this time we'll pull down the top 50 candidates:
# Send search request
use_sql = False # We are just focusing on elasticsearch syntax
size = 50 # number of results to pull down (up to 100)
success, results = send_person_search_request(query, use_sql, size)
# Count total number of results:print(f"Total number of matches in PDL database: {results['total']}")
# Look at results:# Number of results pulled down:print(f"Number of records retrieved: {len(results['data'])}")
# Job title and locations of matches:for idx, profile in enumerate(results['data']):
print(f"{idx+1}) "
f"Job Title: {profile['job_title']} - "
f"Location: {profile['location_country']}")
# Save profiles to csv (and download):# Note: You may need to enable browser permissions to download files
filename = 'candidate_profiles_improved_query.csv'
save_profiles_to_csv(results['data'], filename)
files.download(filename)
Total number of matches in PDL database: 730162
Number of records retrieved: 501) Job Title: vice president operations, general counsel - Location: united states
2) Job Title: lead ios software engineer - Location: united states
3) Job Title: project manager and scrum master and agile optimizer - Location: united states
4) Job Title: founder - Location: united states
5) Job Title: senior sofware developer - Location: united states
6) Job Title: product director - Location: united states
7) Job Title: director, delivery - Location: united states
8) Job Title: senior information security engineer - Location: united states
9) Job Title: senior site reliability engineer - Location: united states
10) Job Title: vice president of enterprise technology and operations - Location: united states
...
41) Job Title: product manager - Location: united states
42) Job Title: founder and chief executive officer - Location: united states
43) Job Title: software development manager - Location: united states
44) Job Title: senior manager, developer experience - Location: united states
45) Job Title: director of test engineering - Location: united states
46) Job Title: software engineer at sfile technology corporation - Location: united states
47) Job Title: engineering manager - Location: united states
48) Job Title: staff software engineer - Location: united states
49) Job Title: software engineer, manager - Location: united states
50) Job Title: product owner - Location: united states
Wrote 50 lines to: 'candidate_profiles_improved_query.csv'
As a result of our improvements, we now see a much better set of candidates and profile matches:
The pool of candidates is much much larger, with over 700,000 total matches
The top 50 profiles are highly targeted and seem very relevant for our job description
At this point, we have successfully built and optimized our query for the Person Search API, which produced a high-quality pool of candidates for our target job description. In our final section, we will explore what we can do to go beyond even these optimizations and truly build expert-level queries for sourcing the best possible candidates.
Expert Query
In this final section, we will explore how to build a query that is maximally optimized for candidate sourcing.
Note: This section will use features of the Person Search API that are not accessible in the free tier. However, if you are interested, you can get access through speaking with one of our data consultants.
Let's begin by trying to understand where some of the shortcomings of our last query were. While the pool of candidates completely improved over our first attempted query, we can still see some areas for improvement in looking at the candidate pool. The main issue in particular is the apparent level of experience of these candidates compared to our job description. For our open roles, we are looking for candidates with at least 3 years of experience, however, some of the profile matches returned are quite senior employees (such as professors, directors, staff-level engineers, etc).
Additionally, as we now move to consider the full feature set of the Person Search API, we also can leverage information contained within the premium, high-value fields (referred to as restricted fields).
Improvements
As a result from our analysis and investigations above, here are a couple ways that we can further optimize our queries:
Restricting the seniority of candidates
Leveraging premium, high-value fields
Let's look at these one-by-one:
Restricting Seniority
Looking through the Person Schema as well as the Restricted Fields Schema, we can find the following fields related to seniority:
experience.title.levels: A canonicalized field representing the seniority of a job title a person has held in the past (see List of Canonical Job Levels)
inferred_years_experience: A restricted field representing the estimated number of years a person has been working
In order to restrict the seniority levels, we can come up with the following criteria:
experience.title.levels must not equal any of [cxo, director, manager, owner, partner, vp]
inferred_years_experience must be greater than or equal to 3 and less than or equal to 10
Translated into Elasticsearch syntax these criteria become:
# Seniority: Must not have a high seniority
seniority_levels = [
"cxo",
"director",
"manager",
"partner",
"vp",
"owner"]
seniority_criteria = {"terms": {"experience.title.levels": seniority_levels}}
# Experience: Must have >=3 and <=10 years work experience in engineering# Restricted field
years_of_experience_criteria = \
{"range": {"inferred_years_experience": {"gte": 3, "lte": 10}}}
Leveraging Restricted Fields
We just saw how the inferred_years_experience restricted field can directly help with focusing the seniority level for candidates. Looking through the Restricted Fields Schema, we can also find the following relevant fields:
summary: A free-text field often similar to a person's linkedin summary
experience.summary: A free-text field containing a person's own summary of an experience
These types of fields are excellent places to find target keywords (such as our required and desired skills, and so we can easily add them into the search criteria we defined before:
# Required Skills (target keywords)# Must have at least one of the target keywords somewhere in profile:
target_keywords = ['javascript', 'react', 'java', 'web frameworks']
target_keywords_criteria = [
{"bool": {
"should": [
{"match": {"summary": kw}}, # Restricted field
{"match": {"experience.summary": kw}}, # Restricted field
{"match": {"experience.title.name": kw}},
{"match": {"interests": kw}},
{"match": {"skills": kw}}
]
}}
for kw in target_keywords
]
# Ideal Skills/Interests (ideal keywords)# Rank results by presence of keywords in profile:
ideal_skills = [
"geospatial",
"customer management",
"analytics",
"data"
"cross-device",
"browser compatible"
"VR",
"AR",
"virtual reality",
"augmented reality"]
# Build nested query for each skill# i.e. for each skill, skill must appear in one of:# [summary, experience.summary, experience.title.name, interests, or skills]
ideal_skills_criteria = [
{"bool": {
"should": [
{"match": {"summary": kw}}, # Restricted field
{"match": {"experience.summary": kw}}, # Restricted field
{"match": {"experience.title.name": kw}},
{"match": {"interests": kw}},
{"match": {"skills": kw}}
]
}}
for kw in ideal_skills
]
Combining Query Improvements
Let's now combine each of these improvements again into a further optimized query:
query = {
"query": {
"bool": {
"must": [
# Location
{"term": {"location_country": "united states"}},
# Education
education_criteria,
# Experience
{"term": {"experience.title.role": "engineering"}},
{"term": {"experience.title.sub_role": "software"}},
# Required Skills
{"bool": {
"should":
target_skills_criteria
}
},
# Contact Info
{"exists": {"field": "linkedin_url"}}
],
"must_not": [
seniority_criteria
],
# Ideal Skills/Interests
"should": ideal_skills_criteria
}
}}
Sending the Query and Retrieving Results
Finally, let's send our fully optimized query as an API request, and this time we will pull down a full list of 2000 profiles that we can use to recruit from.
# Send search request
num_desired_matches = 2000 # We want 2000 candidate profiles in totaldef send_request_func(size, scroll_token):
success, results = send_person_search_request(query, False, size, scroll_token)
return success, results
success, total, results = \
retrieve_search_api_matches(send_request_func, num_desired_matches)
# Look at results:# Number of results pulled down:print(f"Number of records retrieved: {len(results)}")
# Job title and locations of matches:for idx, profile in enumerate(results):
print(f"{idx+1}) "
f"Job Title: {profile['job_title']} - "
f"Location: {profile['location_country']}")
# Save profiles to csv (and download):# Note: You may need to enable browser permissions to download files
filename = 'candidate_profiles_expert_query.csv'
save_profiles_to_csv(results, filename)
files.download(filename)
Total Number of Matches: 411217
Number of records retrieved: 20001) Job Title: senior sofware developer - Location: united states
2) Job Title: senior information security engineer - Location: united states
3) Job Title: ios engineer - Location: united states
4) Job Title: senior software engineer - Location: united states
5) Job Title: software engineer - Location: united states
6) Job Title: salesforce developer at edgecast networks - Location: united states
7) Job Title: senior software engineer - Location: united states
8) Job Title: software engineer at sfile technology corporation - Location: united states
9) Job Title: staff software engineer - Location: united states
10) Job Title: senior software engineer - Location: united states
...
1991) Job Title: pm - Location: united states
1992) Job Title: software engineer - Location: united states
1993) Job Title: quality assurance engineer - Location: united states
1994) Job Title: staff software engineer - Location: united states
1995) Job Title: computer scientist - Location: united states
1996) Job Title: software architect - Location: united states
1997) Job Title: senior software engineer - Location: united states
1998) Job Title: staff software engineer - Location: united states
1999) Job Title: software engineer - Location: united states
2000) Job Title: senior software engineer - Location: united states
Wrote 2000 lines to: 'candidate_profiles_expert_query.csv'
Looking at the job titles among our top 2000 profile matches shows that these candidates are even more targeted than our previous query based on our job description. While there are still some relatively senior candidate profiles present, the vast majority seem to be well-suited for our open position.
Conclusion
We finally made it to the end of this recruiting tutorial! If you stuck with this and followed along, you learned quite a bit about the Person Search API and the value there is in constructing targeted and optimized queries.
The Person Search API gives you full control over the process of generating and sourcing high-quality talent from our dataset of over 2 billion person profiles, with enough depth to uncover truly hard-to-find talent as well as the flexibility to accommodate staffing needs for nearly any type of position imaginable. With our examples, we saw first-hand the value of building and refining our search queries as we worked from our first query all the way up to an expert-level query. The result of this process was a list of 2000 highly qualified candidates that we could immediately begin reaching out to and recruiting for a hard-to-fill software engineering role with a relatively niche skillset requirement.
Although our most advanced queries were beyond the scope of the free tier, using the Person Search API costs a fraction of a dollar per lead, which is well worth the expense of a successful and qualified hire. As we mentioned at the beginning of this article, PDL has its history in the talent acquisition and recruiting space, and the processes covered in this tutorial are illustrative of how we source candidates for our own openings as well.
Wrapping Up
Hopefully, this tutorial was illustrative and helpful in getting you up to speed with using the Person Search API for a recruiting use case. If you are interested in other applications of the Person Search API and some other products PDL offers, please checkout our other use case tutorials as well (such as our B2B Audience Generation and Investment Research tutorials). Keep an eye out for our next tutorial in the PDL Use Case Series, and in the meantime, we encourage you to play around further with this notebook and the other tutorial notebooks and to reach out with any questions you might have!
Need more data or credits? Want access to premium fields? Speak to one of our data consultants today!
Like what you read? Scroll down and subscribe to our newsletter to receive monthly updates with our latest content.




