
Investment Research [In-Depth Tutorial]
April 15, 2021
Table Of Contents
Introduction
Welcome to the second installment in our Use Case Series! In this tutorial, we’ll take a look at an Investment Research use case and explore how to leverage PDL's Company Enrichment API and Person Search API for both sourcing and contextualizing potential investment opportunities.
The only things you will need to get started with this tutorial are:
This tutorial can be read without reading any of the previous tutorials. However, we will point back to a few relevant sections in our first tutorial for additional details. A basic familiarity with Python and Google Colaboratory will be helpful for reading and interacting with the code in this tutorial.
Getting a Free PDL API Key
Sign up for a Free PDL API Key by filling out the form on the signup page. For a detailed walkthrough of this process, take a look at our Self-Signup API Quickstart Guide.
Setting up Colab
First, open up the Colab notebook, and make a copy of it by clicking “File > Save a copy in Drive” from the toolbar.
Copying the colab notebook.
Next, once you have your API key, enter into the cell block shown below (and don't forget to run the cell!).
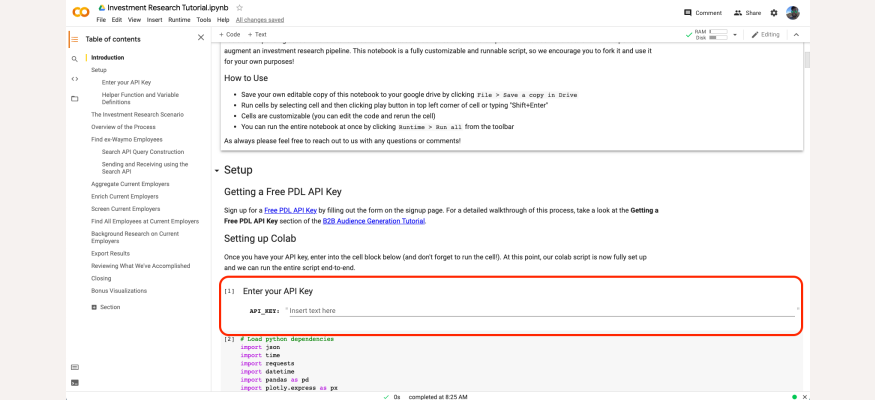
Enter your API key the colab cell indicated.
Again make sure to run the cell by hitting “Shift+Enter”, or clicking the play button in the top left corner of a cell that appears when hovering over the cell.
A Quick Note about Helper Function Definitions
The Setup section of the notebook also defines several utility functions that we will make use of throughout the tutorial. These functions help in the process of sending and receiving API requests and responses (such as managing rate limiting, checking error responses, and retrieving match results in batches). Run the cell to load these function definitions.
This cell block is hidden by default, but we definitely encourage you to open up the cell block and take a look at the implementations. You can do so by clicking the “SHOW CODE” block shown in the following image. Note: you can also hide the block again by double clicking the whitespace on the right side of the expanded code block after opening it.
Helper function definitions in the colab notebook (click "SHOW CODE" to expand).
At this point, we are all done with the setup and our Colab notebook is fully set up to run the entire script end-to-end. Now, let’s take a look at the scenario we’ll explore in this tutorial.
The Investment Research Scenario
Imagine we are an investment firm looking for new investment opportunities in the autonomous vehicles space. Our firm focuses on very early-stage startups (≤ 3 years old) with a strong technology offering and high-growth potential.
Recently (as of April 2021), John Krafcik announced that he would be stepping down as CEO of Waymo, Alphabet's self-driving subsidiary. This news may also signal the departure of other employees, and so to source new investment opportunities, our firm has decided to target former Waymo employees and investigate what companies these employees have gone to. In particular, we'd like to focus on employees in engineering roles as we believe they serve as a strong positive indicator for the technological strength of their new employers. For each of these companies, we would like to do some initial screening and background research to come up with a small handful of candidates matching our investment profile to bring to the table for internal discussion.
Overview of the Process
To summarize our approach to this task, here's a high-level breakdown of what we'll cover in the remainder of this tutorial.
Find ex-Waymo Engineers: Pull profiles of all former Waymo engineering employees using the Person Search API
Aggregate Current Employers: Group all the companies that our former Waymo employees currently work at
Enrich Current Employers: Use the Company Enrichment API to pull additional metadata for each company in our list
Screen Current Employers: Filter out companies that do not fit our target investment profile
Find All Employees at Current Employers: For each of the remaining companies, pull profiles for all current and past employees using the Person Search API
Background Research on Current Employers: Use the combination of company enrichment data and current/past employee profiles to generate insights into each company
Export Results: Export our profile lists, company matches and background research for use in other analysis pipelines
Find ex-Waymo Employees
Our first task is to find ex-Waymo employees, which can be easily done using the PDL Person Search API.
Before pulling person profiles, however, we will want to standardize our company information for Waymo in order to ensure consistency with the way data is represented in PDL's databases (for example, like the way names are spelled or urls are formatted). This is referred to as 'cleaning' our data and can be done using either PDL's Company Enrichment API or the dedicated Company Cleaner API.
For this tutorial, we will use the Company Enrichment API to get the internal PDL Company ID for Waymo (which we can then use to find people associated with Waymo):
# First let's enrich Waymo to get its PDL Company ID# We can use this ID to then find people associated with Waymo (as we'll see)
# We supply some basic information for the Company Enrichment API# The available parameters we can provide are described at:# https://docs.peopledatalabs.com/docs/company-enrichment-api#input-parameters
company_params = {
"website": "waymo.com",
"name": "waymo"}
# We'll send a simple company enrichment request
success, response = send_company_enrichment_api_request(company_params)if success:
company_id = response['id']
print(f"Success! Found enrichment and company id: {company_id}")else:
print(f"Couldn't find company id for: {company_params}")
Success! Found enrichment and company id: waymo
The code snippet above is a simple instance of sending a Company Enrichment API request. We use the helper function send_company_enrichment_api_request() to handle sending the request (along with handling error checking and rate limiting). For a successful API request, the response object will contain all the company enrichment data for that request, including the id field we are after. Feel free to take a look at an example of a full company enrichment response to learn what additional data is provided through the Company Enrichment API.
Now that we have a standardized way to reference Waymo using its id field, we can use that to construct a Person Search API query for ex-Waymo engineers as follows:
# Now that we have the company id for Waymo, we can use the Person Search API to# find all former waymo employees who worked in engineering roles
# Building our query for the Person Search API# We can use Elasticsearch to define our query# Documentation: https://www.elastic.co/guide/en/elasticsearch/reference/7.7/query-dsl.html
es_query = {
"query" : {
"bool": {
"must": [
{"term": {"experience.company.id": company_id}},
{"term": {"job_title_role": "engineering"}}
],
"must_not": [
{"term": {"job_company_id": company_id}}
]
}
}}
# Or we can use SQL to define the same query# Documentation: https://www.elastic.co/what-is/elasticsearch-sql
sql_query = f"SELECT * FROM person "\
f"WHERE experience.company.id = '{company_id}' "\
f"AND job_title_role = 'engineering'"\
f"AND job_company_id <> '{company_id}'"
Search API Query Construction
As we can see, there are 2 ways of structuring queries for the Person Search API: we can use Elasticsearch query syntax or SQL, which the code snippet above demonstrates. While the Elasticsearch syntax is a bit more complex, it is generally recommended over SQL for querying the PDL API's since it is more flexible and maps more naturally onto PDL's internal search mechanisms.
Regardless of the syntax used, however, the query built in the code block specifies the following logical criteria for a valid profile match:
The person must have worked at Waymo
They must be working in an engineering role
They must not be currently working at Waymo
Translating these search criteria into code requires an understanding of the representation of fields within our Person Schema, so let's briefly take a closer look:
Criteria 1 (The person must have worked at Waymo)
For this constraint, the related schema field is the experience.company.id field, which represents the id for any company that a person has ever worked at. In PDL's person schema, the experience field is an array where each element represents a single job experience. We specify that a valid person match must have at some point worked at Waymo by stating that experience.company.id must equal the company id for Waymo (which we got from the initial company enrichment we did).
Criteria 2 (They must be working in an engineering role)
The second constraint uses the job_title_role field, which represents the current type of job that a person has. PDL has defined a set of canonical job roles that enumerate all values this field can take on, of which engineering is one such enumerated value. Thus, we specify that a valid match must be working in an engineering role by requiring that job_title_role must equal “engineering”.
Criteria 3 (They must not be currently working at Waymo)
The last constraint uses the job_company_id schema field, which represents the company id for a person's current employer. By requiring that job_company_id must not equal the company id for Waymo, we can enforce that the profile match is not a current Waymo employee.
Taken together, these 3 criteria are how we can define our search query for ex-Waymo engineers. While there are multiple ways to define most queries, this clarifies the reasoning behind one such approach to constructing queries for the Person Search API. If you would like to build your own queries, we highly encourage familiarizing yourself with the available fields in the Person Schema.
Sending and Receiving using the Search API
Now that we've seen how to build our search query, let's finish up this section by looking at how we send it and pull down profiles matching our criteria for ex-Waymo engineers:
# Send our Person Search API query (you can use_sql to determine whether to
# query using Elasticsearch or SQL syntax)
use_sql = False
query = es_query if not use_sql else sql_query
# We want to get all the possible search matches, so we will pick a large number
# like 10,000 for our desired number of match results. However, by default a
# single search api request will return a maximum of 100 matches.
# So in order to retrieve more than 100 matches we will have to pull down
# results in batches, which is what the helper function
# retrieve_search_api_matches() does for us.
# Note: the helper function will print out a warning if it is unable to
# recover the desired number of matches (which it will in this case)
num_desired_matches = 10000
def search_api_request_func(size, start_from):
return send_person_search_request(query, use_sql, size=size, start_from=start_from)
ex_employees = retrieve_search_api_matches(search_api_request_func, num_desired_matches)
print(f"Successfully retrieved {len(ex_employees)} ex-Waymo engineers")
Total Number of Matches: 225
WARNING: Person Search API found [225] total matches which is less than the desired number matches [10000]
Successfully retrieved 225 ex-Waymo engineers
Our goal is to recover all the profiles matching our search query. However, the Person Search API does not allow us to retrieve more than 100 profile matches at a time (see the size parameter description in the docs). So instead, we must pull the results down in batches, which is what the retrieve_search_api_matches() helper function does for us, as seen in the code block above. This function sends a query multiple times each time incrementing the batch starting position until all results have been pulled down. We use the send_person_search_request() helper function to handle sending the actual query request (which manages error checking and rate limiting). For additional information on this process, see the Sending the Query and Retrieving the Results section in the B2B Audience Generation Tutorial.
The end result is that we have successfully pulled down every available profile in the PDL database matching our query for ex-Waymo engineers.
Aggregate Current Employers
After pulling all the profiles of ex-Waymo engineers from the Person Search API, we now want to look at where all these people are currently employed. This can be done quite simply by iterating over our profiles and aggregating each profile's current employer. Knowing that we will want to enrich these companies in the next step, we will also make sure to keep track of the necessary information to use as input for the Company Enrichment API (e.g. name, website, and linkedin_url for each company). This is demonstrated in the code snippet below:
# Find where all our ex-Waymo employees are currently working:
# We'll simply iterate through our list of ex-Waymo employees and keep track of# all the different companies they work at currently as well as how many waymo# employees went to the same company.
current_employers = {}for person in ex_employees:
company_id = person['job_company_id']
# If this is the first time we've seen this company then initialize some info
# such as:
# count - keep track of number of ex-waymo engineers working there
# params - name, website, linkedin so that we can enrich this company later
if company_id not in current_employers:
current_employers[company_id] = {
"count": 1,
"params" : {
"name" : person['job_company_name'],
"website": person['job_company_website'],
"linkedin_url": person['job_company_linkedin_url']
}
}
else:
current_employers[company_id]['count'] += 1
# Store our result as a list (e.g. flatten it)
current_employers_list = [value for key, value in current_employers.items()]
print(f"Found {len(current_employers_list)} "\
f"companies employing ex-Waymo engineers")
Found 124 companies employing ex-Waymo engineers
Enrich Current Employers
As mentioned in the previous step, we now want to enrich this list of companies employing former Waymo engineers. Here, our goal in doing this enrichment is to collect additional metadata on each company that will be useful in later steps: for both screening out companies that do not fit our target investment profile, as well as providing extra contextual information to supplement our background research.
To enrich these companies, we simply iterate over each company in our list, send and an enrichment request and collect the responses in an array:
# Now we'd like to enrich each of these companies so that we can later do an# initial screening of these companies# Note: This process can take a few minutes to complete all the enrichment# requests. Any requests that fail will be printed in the output.
enriched_companies = []
num_success = 0for company in current_employers_list:
company_params = company['params']
success, enrichment = send_company_enrichment_api_request(company_params)
if success:
enriched_companies.append(enrichment)
num_success += 1
else:
enriched_companies.append({})
print(f"Failed to enrich: {company_params}")
print(f"Successfully enriched {num_success} "\
f"out of {len(enriched_companies)} companies")
Error: 404 [not_found] - No records were found matching your request
Failed to enrich: {'name': None, 'website': None, 'linkedin_url': None}
Error: 404 [not_found] - No records were found matching your request
Failed to enrich: {'name': 'newco', 'website': None, 'linkedin_url': 'linkedin.com/company/go-aigua1'}
Successfully enriched 122 out of 124 companies
As before, we use the send_company_enrichment_api_request() helper function to submit the enrichment requests and handle error checking as well as rate limiting.
Having run the enrichments, let's take a minute to explore the set of companies currently employing ex-Waymo engineers:
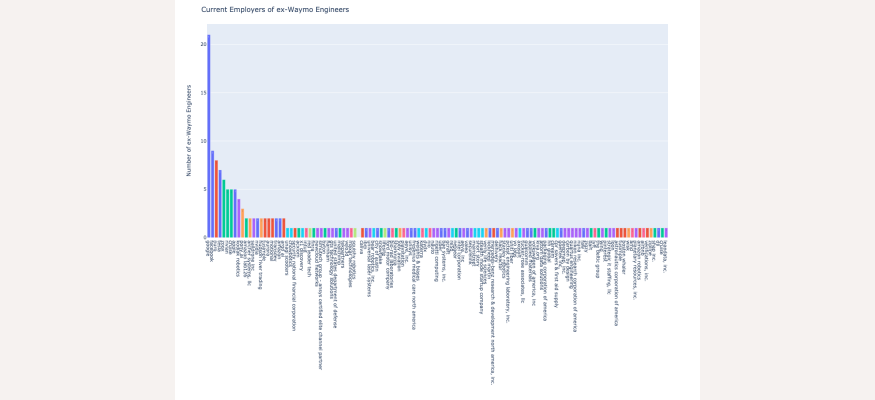
Histogram of current employers of ex-Waymo engineers. Bar height indicates number of ex-Waymo engineers hired, and bar color indicates total company size.
The figure above shows a histogram of all the current employers of ex-Waymo engineers, with bar height indicating the number of ex-Waymo engineers and bar color indicating the size of the company. Unsurprisingly, most of the former Waymo engineers end up at larger companies (with Google itself taking the lead). However, there are a few smaller companies with multiple former Waymo engineers. Overall, we can see that Waymo engineers have left for companies of all different sizes, which means we will likely be able to find some investment candidates.
Screen Current Employers
At this point, we would like to do some initial screening to exclude companies that are far outside our typical investment profile, which is very early stage companies with strong technology products. We'll rely on the fact that these companies all employ former Waymo engineers to satisfy our requirement for a strong technology product, and instead, focus our screening on companies that are beyond our typical upper-bound size and age profiles:
# We want to focus on companies that are less than 5 years old and ≤50 employees
candidates = []for company in enriched_companies:
if 'status' in company and company['status'] == 200 and company['founded']:
# Compute the age by looking at the year the company was founded
age = datetime.datetime.today().year - int(company['founded'])
# Check whether the company size matches our criteria
is_small_enough = company['size'] == "1-10" or company['size'] == "11-50"
if age <= 5 and is_small_enough:
candidates.append(company)
print(f"Found {len(candidates)} candidate companies after screening")
Found 6 candidate companies after screening
As seen in the code block above, this type of screening process is quite simple to implement and serves as a coarse filter for discarding clearly poor fits. After screening, we are left with just a handful of companies we aim to take a deeper look at.
Find All Employees at Current Employers
In order to better understand each of these companies, we will want to pull all the associated person profiles for each company (e.g. all current/former employees), which will allow us to better understand the demographics and growth profiles of these companies. In order to pull all employees, we will again use the Person Search API like we did in the Find ex-Waymo Employees section as shown in the following code block:
# Now let's pull all the current and former employee profiles for each of# the companies remaining after screening. We'll use the Person Search API# again, this time iterating over each company with a slightly modified# (and simpler) query from before.
candidates_all_employees = []
total = 0
# We'll iterate over each company and query for all employees at eachfor company in candidates:
# Note that the company enrichment may have failed for some companies
# in which case we will skip them (since we do not have the
# necessary information to query for employees with)
if 'status' not in company or company['status'] != 200:
print(f"Previous enrichment had failed so skipping: {company}")
candidates_all_employees.append({})
continue
print(f"Company: {company['name']}")
# Let's build a query to find all current and former employees at this company
# Here's the query using Elasticsearch query syntax:
es_query = {
"query" : {
"bool" : {
"must" : [
{"term": {"experience.company.id": company['id']}}
]
}
}
}
# Here's the same query using SQL:
sql_query = f"SELECT * FROM person "\
f"WHERE experience.company.id = '{company['id']}'"
# Set use_sql accordingly depending on which query syntax you want to use
use_sql = True
query = es_query if not use_sql else sql_query
# Same as before we'll use the retrieve_search_api_matches() helper function
# to pull down match results in batches, and we'll use the
# send_person_search_request() helper function to send the actual search API
# requests.
def send_request_func(size, start_from):
return send_person_search_request(query, use_sql, size, start_from)
employees = retrieve_search_api_matches(send_request_func, num_desired_matches=10000)
# Store all the retrieved employee matches for this company
candidates_all_employees.append(employees)
total += len(employees)
print(f"Total Matches found: {total}")
Company: unagi scooters
Total Number of Matches: 84
WARNING: Person Search API found [84] total matches which is less than the desired number matches [10000]
Company: red leader tech
Total Number of Matches: 10
WARNING: Person Search API found [10] total matches which is less than the desired number matches [10000]
Company: squishy robotics
Total Number of Matches: 41
WARNING: Person Search API found [41] total matches which is less than the desired number matches [10000]
Company: bear robotics, inc.
Total Number of Matches: 83
WARNING: Person Search API found [83] total matches which is less than the desired number matches [10000]
Company: dydx
Total Number of Matches: 36
WARNING: Person Search API found [36] total matches which is less than the desired number matches [10000]
Company: mainstreet
Total Number of Matches: 28
WARNING: Person Search API found [28] total matches which is less than the desired number matches [10000]
Total Number Search API Matches found: 282
As you can see, this code is almost exactly identical to the code we used to pull all ex-Waymo engineers. The only difference is that we are using a slightly modified (and simpler) query and repeating this process for each company in our list.
Background Research on Current Employers
Having narrowed down our list of candidate companies and having pulled down all the related employee profiles for each company, we can now do some deeper investigation to help further inform the investment quality of these remaining candidate companies. For this section, we will define a background_research() helper function to generate the background information and data, and then simply call this function for each candidate company as follows:
# We'll iterate over each candidate company (along with its list of employees)# and generate background information as well as metrics using the# background_research() helper function defined in the code block above
all_background_info = []
all_metrics = []
for company, employees in zip(candidates, candidates_all_employees):
# Generate background information and metrics
background_info, metrics = background_research(company, employees)
# Store background information and metrics in arrays
all_background_info.append(background_info)
all_metrics.append(metrics)
Generating background information on unagi scooters
Generating background information on red leader tech
Generating background information on squishy robotics
Generating background information on bear robotics, inc.
Generating background information on dydx
Generating background information on mainstreet
This section is meant to be more illustrative than exhaustive in terms of demonstrating the types of insights available in the data, and so we won’t dive into the details of the helper functions here. We do encourage you to look at the code implementation in the notebook however! There are many things that can be done, and here are just a few examples implemented in the background_research() helper function:
Generating various top 10 lists (e.g. for skills within the company, previous employers, past universities)
Historical headcount and growth metrics
Distributions of job roles within the company
FYI: Checkout the Bonus Visualizations section at the end of this tutorial, which demonstrates some of the types of visualizations that can be created from the data generated in this section.
Export Results
Finally, our last step is to export these results for use in further analysis and investigation processes. We'll output our results in csv, a straightforward process using the pandas library, as shown in the following code block:
# Finally, let's export and download our results to csv# NOTE: you might need to enable browser permissions to download multiple files
# All former waymo engineers:
csv_filename = 'ex-waymo-employee-profiles.csv'
pd.json_normalize(ex_employees).to_csv(csv_filename)
files.download(csv_filename)
# All current employers of former waymo engineers:
csv_filename = 'ex-waymo-current-companies.csv'
pd.json_normalize(enriched_companies).to_csv(csv_filename)
files.download(csv_filename)
# Screened Candidate Companies and Background Research:
csv_filename = 'screened-candidate-companies.csv'
pd.DataFrame(all_background_info).to_csv(csv_filename)
files.download(csv_filename)
Reviewing What We've Accomplished
In this tutorial, we explored how we could use PDL's data and APIs to support an investment research use case. We first sourced a list of potential investment opportunities by targeting former Waymo engineers and aggregated the set employers they currently work for. Next, we enriched these companies and did some basic screening to narrow our focus down to a handful best matching our target profile. And finally, we dove deeper on the remaining companies by pulling their employees and computing growth metrics and other demographic-related information.
At the end of this process, we now have a targeted selection of investment candidates that match our target profile, and even the contact information for all the employees currently working at each company.
Along the way, we also stepped through a complete python implementation of this audience generation pipeline provided by our Colab notebook, which can be customized to support your particular application or even other use cases such as lead generation, direct outreach, and talent acquisition among others.
Closing
We hope this tutorial illustrates the immediate value that person data can provide, and shows just how easy it is to get started using person data in your business. We encourage you to sign up for a free API key, and give the investment research Colab notebook a spin! As always, please reach out if you have any questions or suggestions, and join us again next time for the third tutorial in this series!
Need more data or credits? Need help customizing your pipeline? Speak to one of our data consultants today!
Like what you read? Scroll down and subscribe to our newsletter to receive monthly updates with our latest content.




